
DART: Disambiguation-Aware Reasoning for Video-guided Machine Translation
Published in CCF A ACL 2026, 2026
Abstract
Video-guided Machine Translation (VMT) seeks to enhance translation quality by incorporating contextual information derived from paired short video clips. However, many VMT samples are text-sufficient; even when visual information is needed, only minimal cues are required. Aiming to tackle these issues, we propose a novel framework DART (Disambiguation-Aware Reasoning for Video-guided Machine Translation). Reinforcement learning is used to incorporate multimodal large language models’ multimodal reasoning into VMT. The model dynamically switches between text-only processing and multimodal integration, contingent on the necessity of visual disambiguation. Furthermore, we present TVRF (Translation-oriented Video Relevance Filtering), a systematic pipeline for constructing training data based on multimodal relevance to translation. This pipeline filters samples where video information is translation-relevant, mitigating training collapse caused by video-irrelevant data in conventional VMT. Experimental results show that our approach improves multimodal information utilization in VMT, yielding gains in both translation quality and computational efficiency.
DART
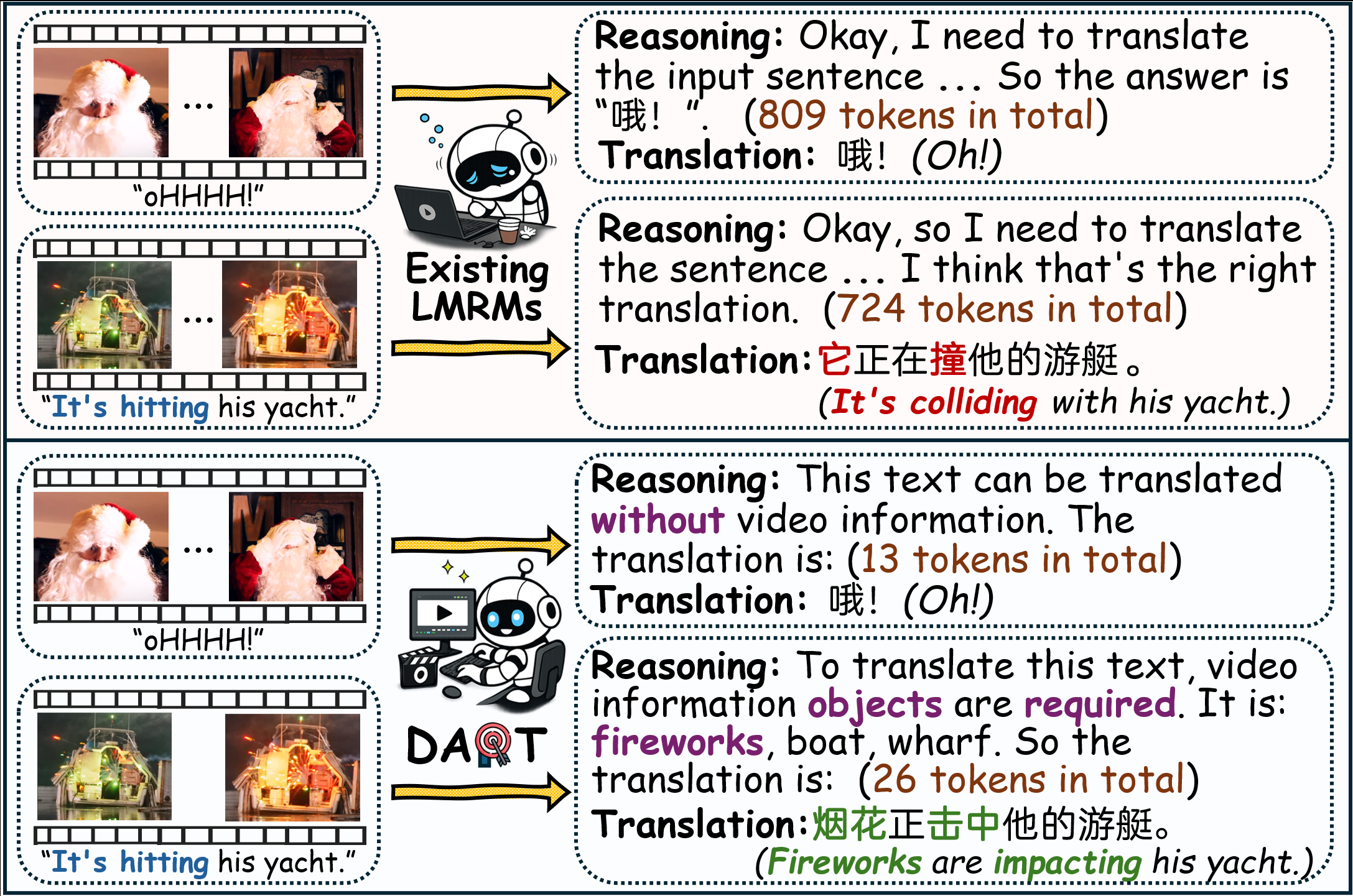
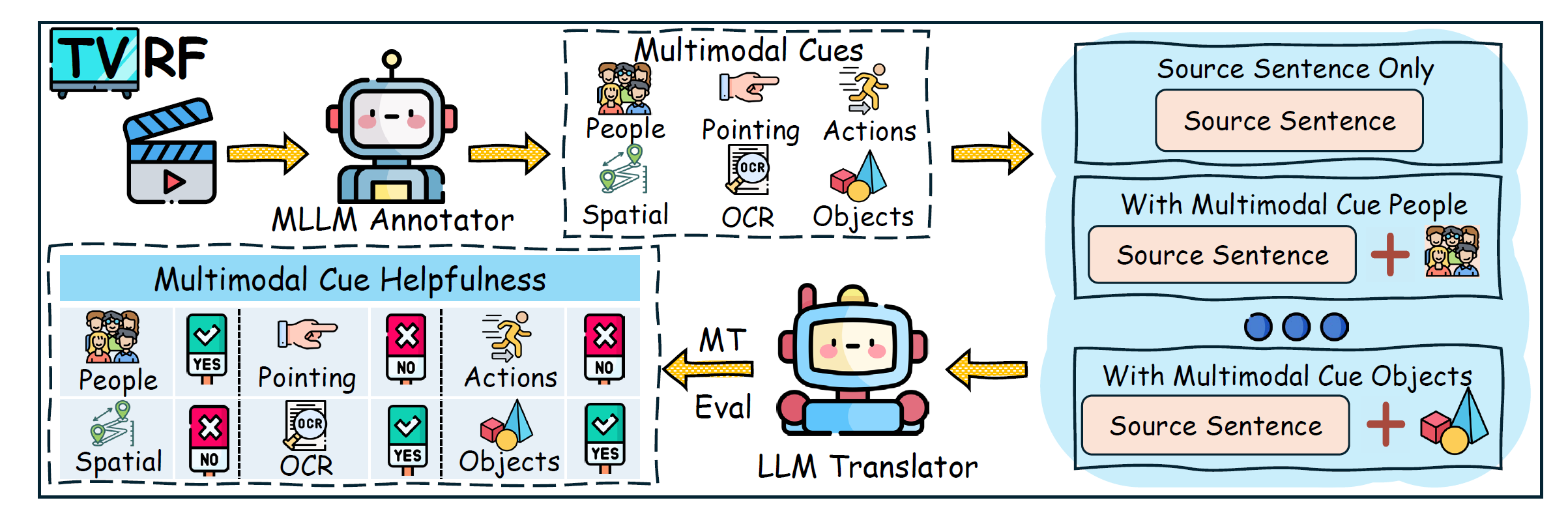
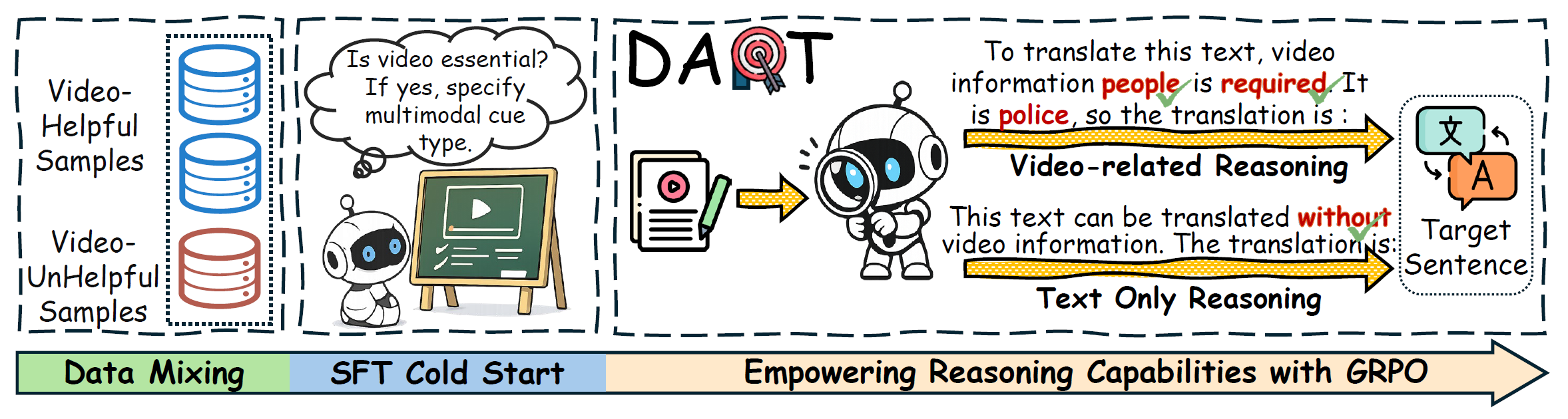
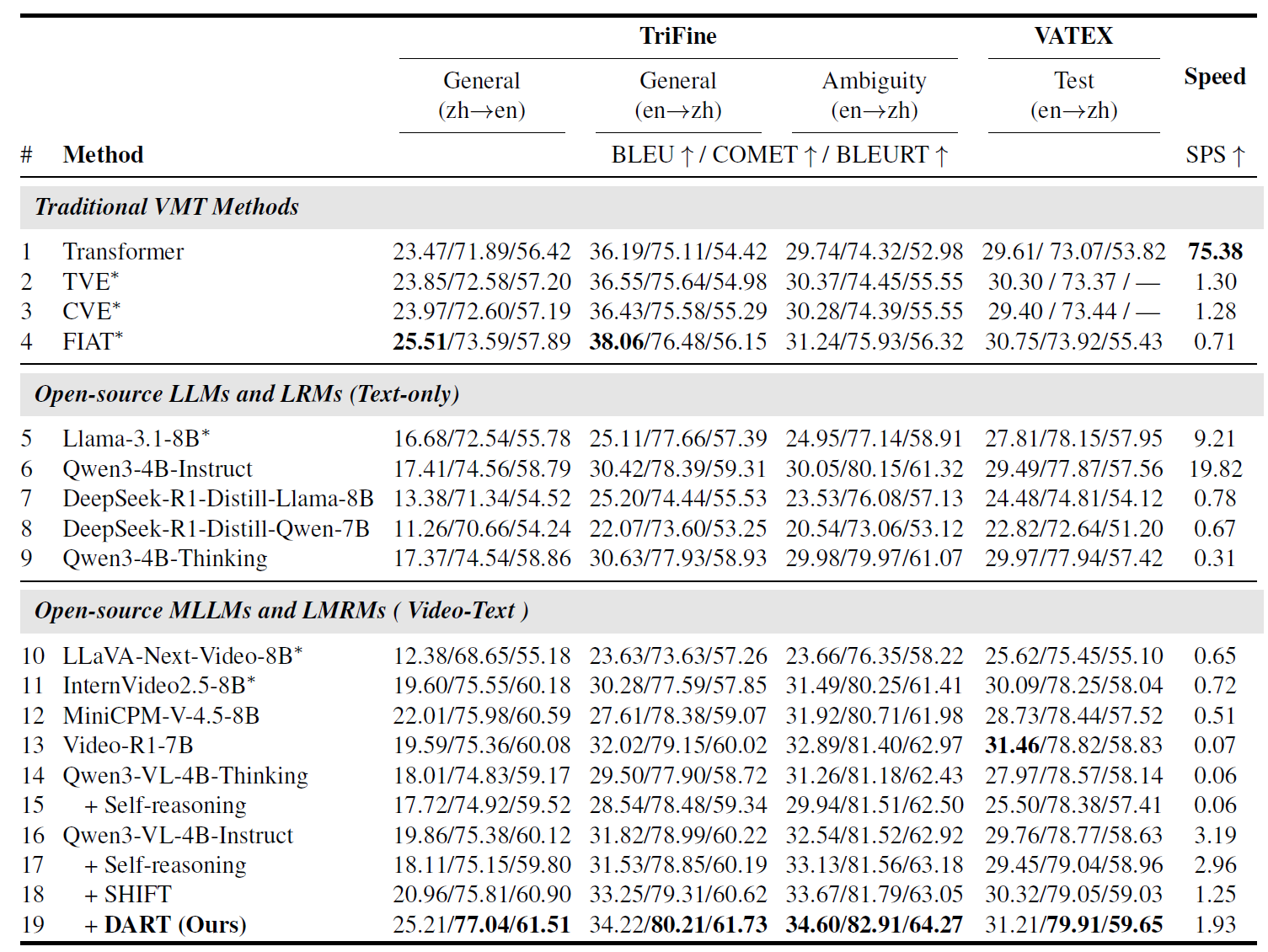
Recommended citation: DART: Disambiguation-Aware Reasoning for Video-guided Machine Translation (Guan et al., ACL 2026)
Download Paper | Code