
SHIFT: Selected Helpful Informative Frame for Video-guided Machine Translation
Published in CCF B EMNLP 2025, 2025
Abstract
Video-guided Machine Translation (VMT) aims to improve translation quality by integrating contextual information from paired short video clips. Mainstream VMT approaches typically incorporate multimodal information by uniformly sampling frames from the input videos. However, this paradigm frequently incurs significant computational overhead and introduces redundant multimodal content, which degrades both efficiency and translation quality. To tackle these challenges, we propose SHIFT (Selected Helpful Informative Frame for Translation). It is a lightweight, plug-and-play framework designed for VMT with Multimodal Large Language Models (MLLMs). SHIFT adaptively selects a single informative key frame when visual context is necessary; otherwise, it relies solely on textual input. This process is guided by a dedicated clustering module and a selector module. Experimental results demonstrate that SHIFT enhances the performance of MLLMs on the VMT task while simultaneously reducing computational cost, without sacrificing generalization ability. The code will be released upon acceptance.
SHIFT
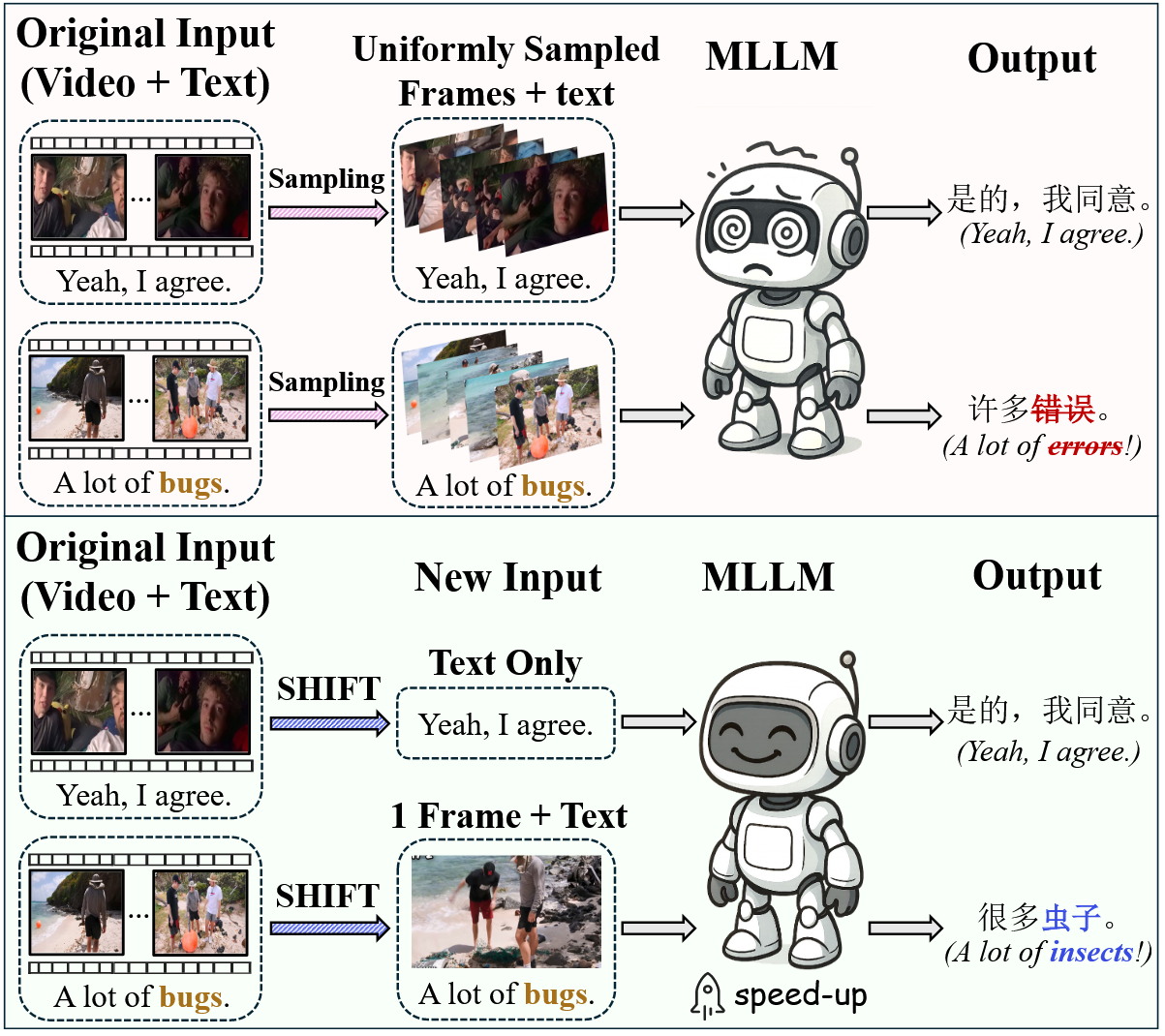
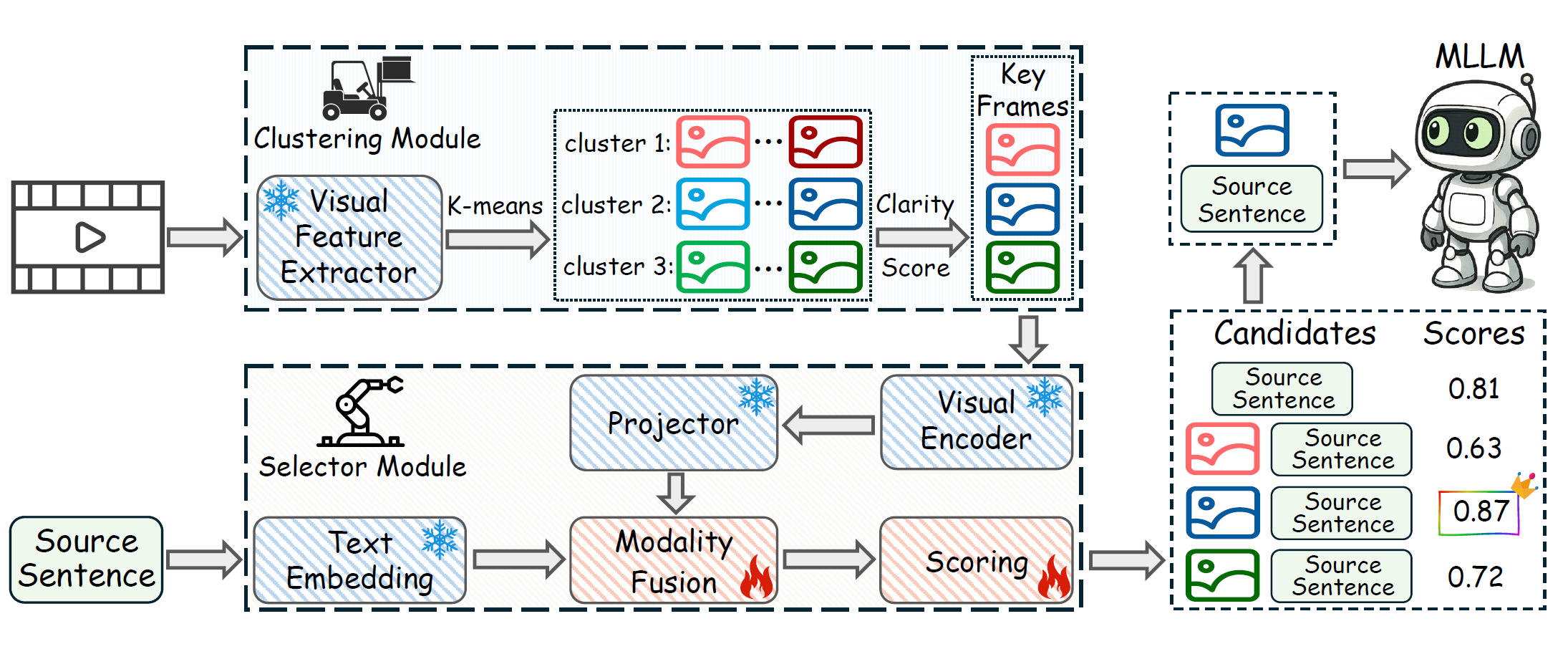
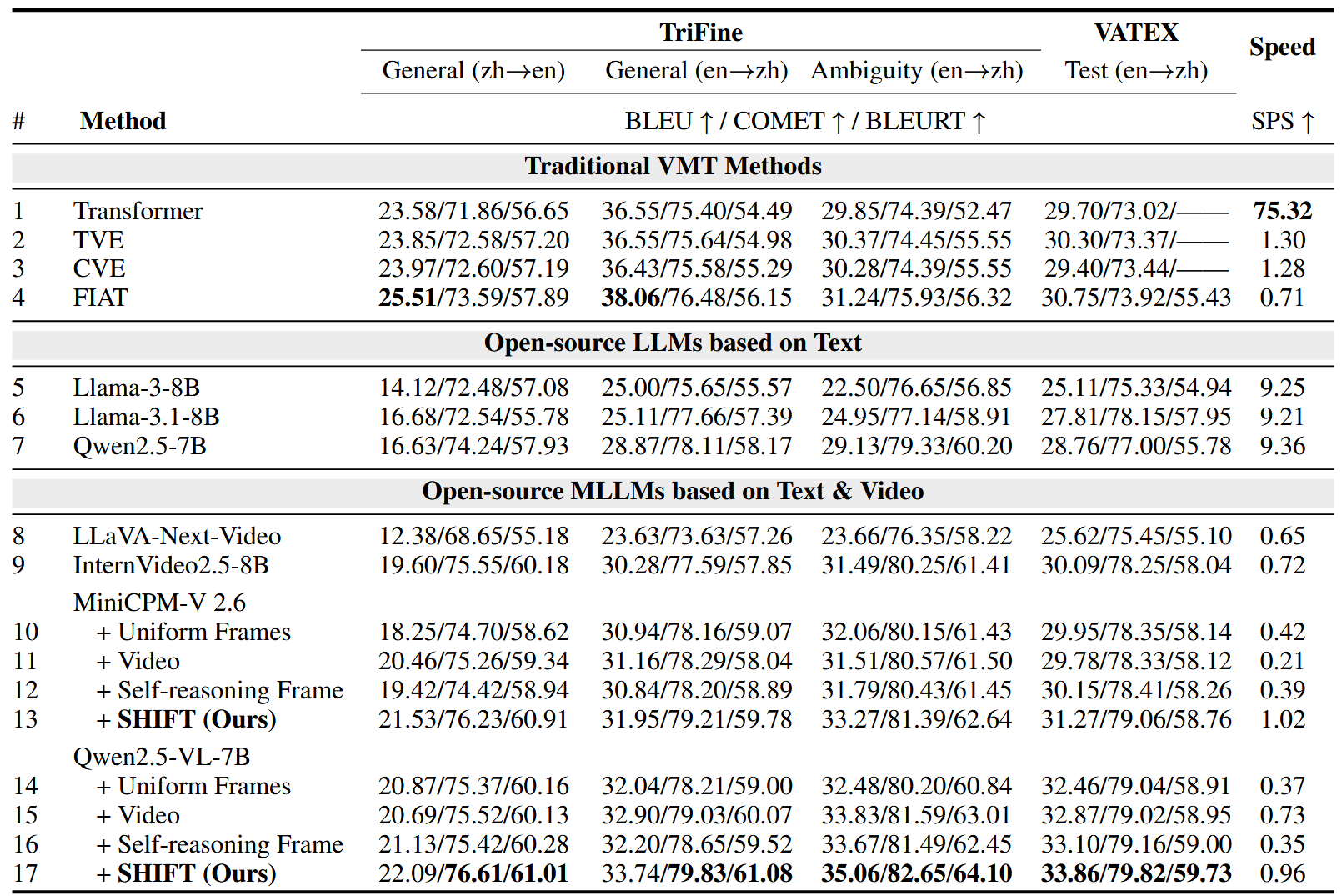
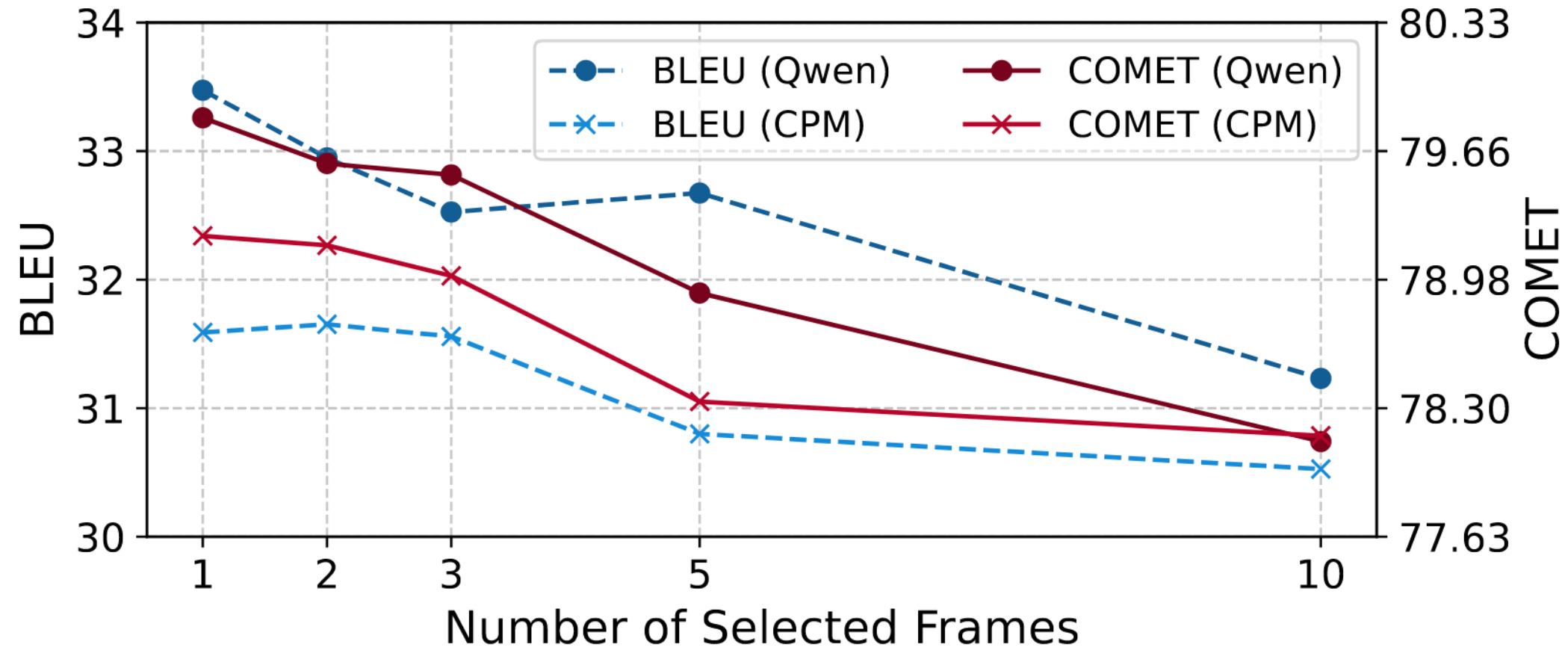
Recommended citation: SHIFT: Selected Helpful Informative Frame for Video-guided Machine Translation (Guan et al., EMNLP 2025)
Download Paper | Code