
TriFine: A Large-Scale Dataset of Vision-Audio-Subtitle for Tri-Modal Machine Translation and Benchmark with Fine-Grained Annotated Tags
Published in CCF B COLING 2025, 2025
Abstract
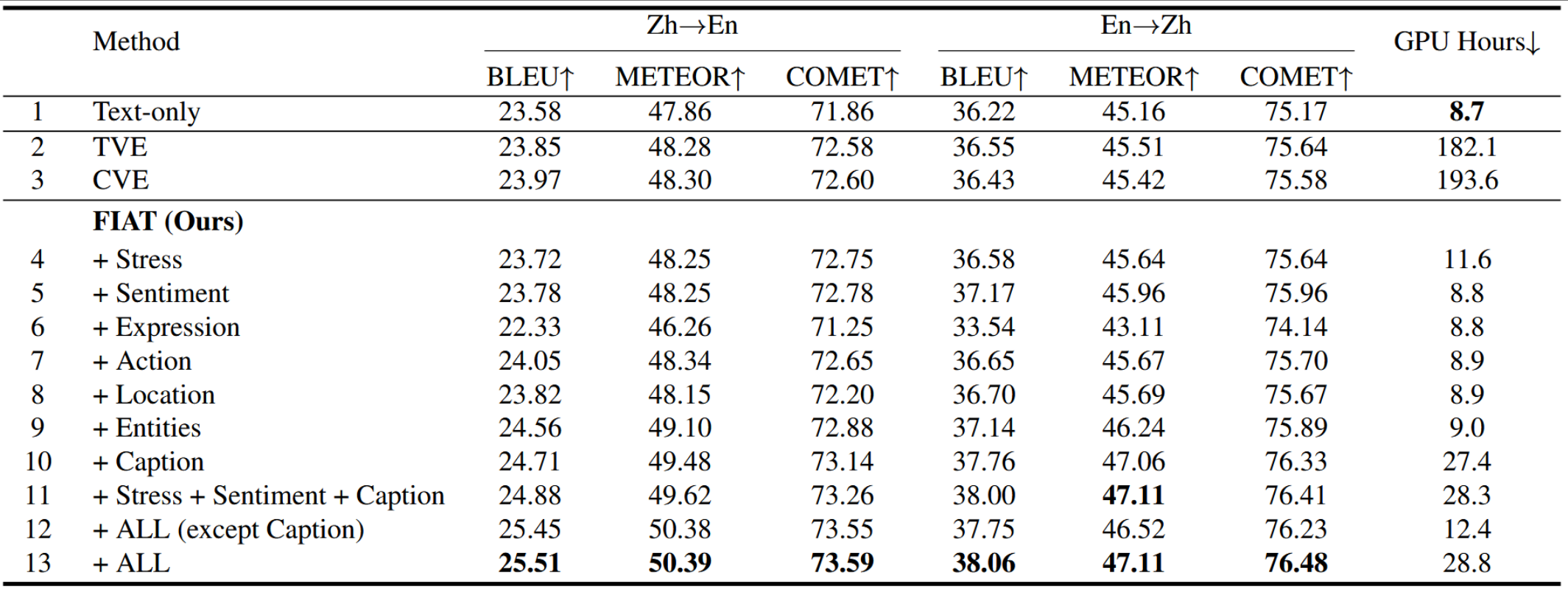
Current video-guided machine translation (VMT) approaches primarily use coarsegrained visual information, resulting in information redundancy, high computational overhead, and neglect of audio content. Our research demonstrates the significance of finegrained visual and audio information in VMT from both data and methodological perspectives. From the data perspective, we have developed a large-scale dataset TriFine, the first vision-audio-subtitle tri-modal VMT dataset with annotated multimodal fine-grained tags. Each entry in this dataset not only includes the triples found in traditional VMT datasets but also encompasses seven fine-grained annotation tags derived from visual and audio modalities. From the methodological perspective, we propose a Fine-grained Information-enhanced Approach for Translation (FIAT). Experimental results have shown that, in comparison to traditional coarse-grained methods and text-only models, our fine-grained approach achieves superior performance with lower computational overhead. These findings underscore the pivotal role of fine-grained annotated information in advancing the field of VMT.
TriFine
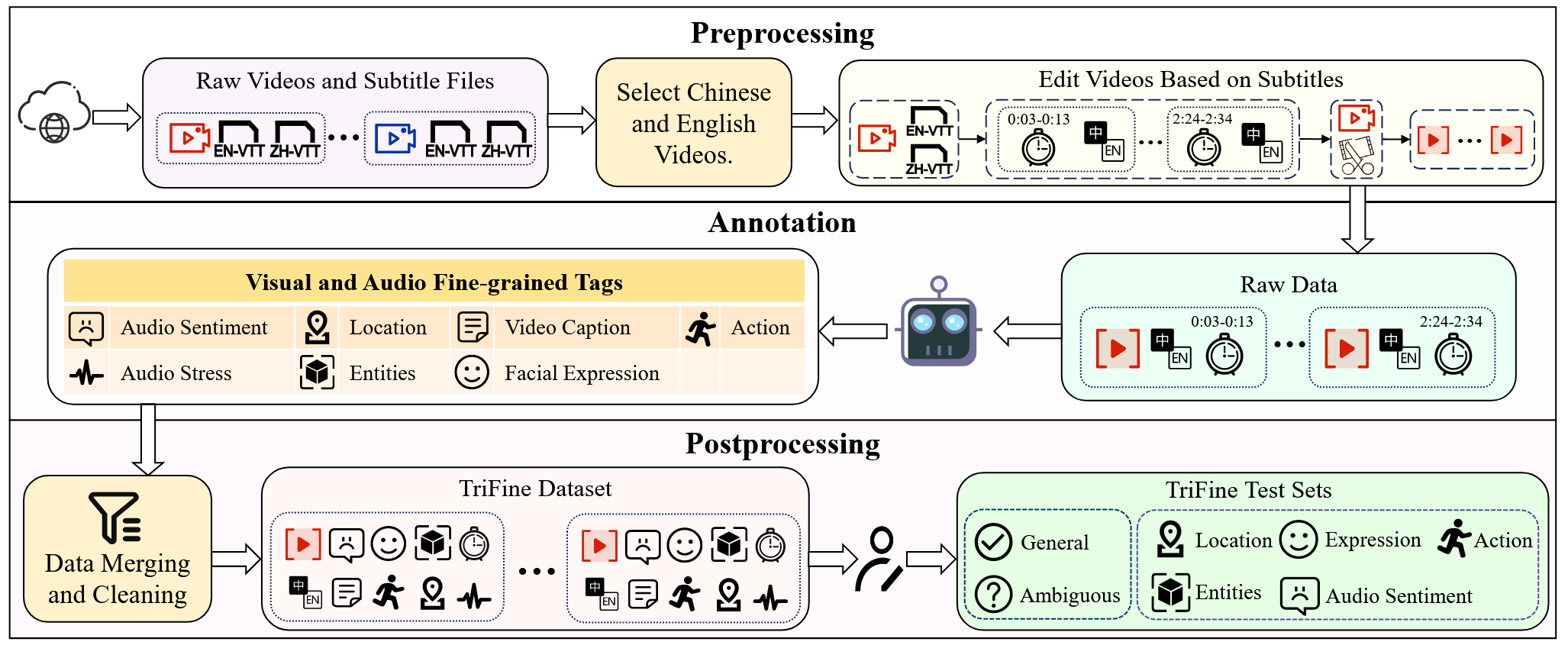
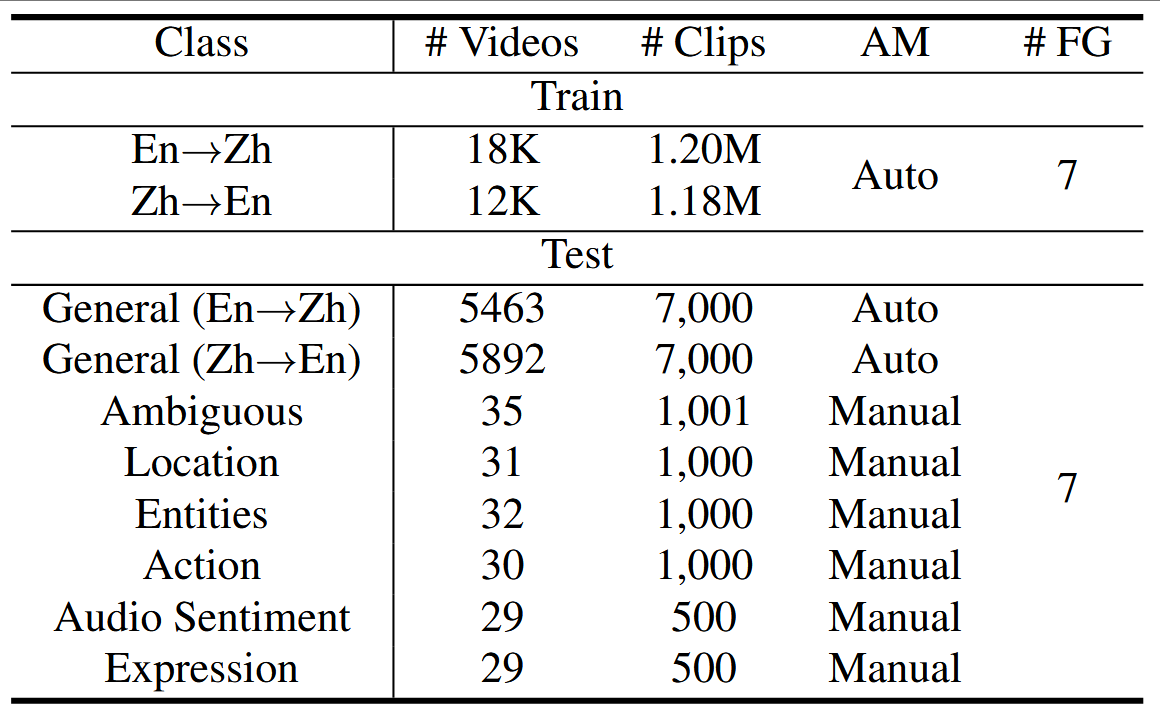
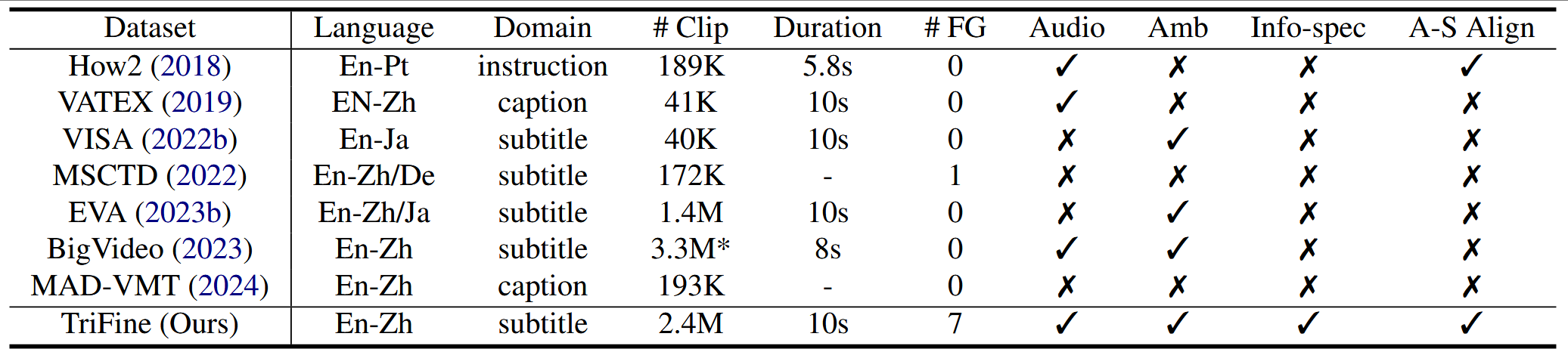
FIAT
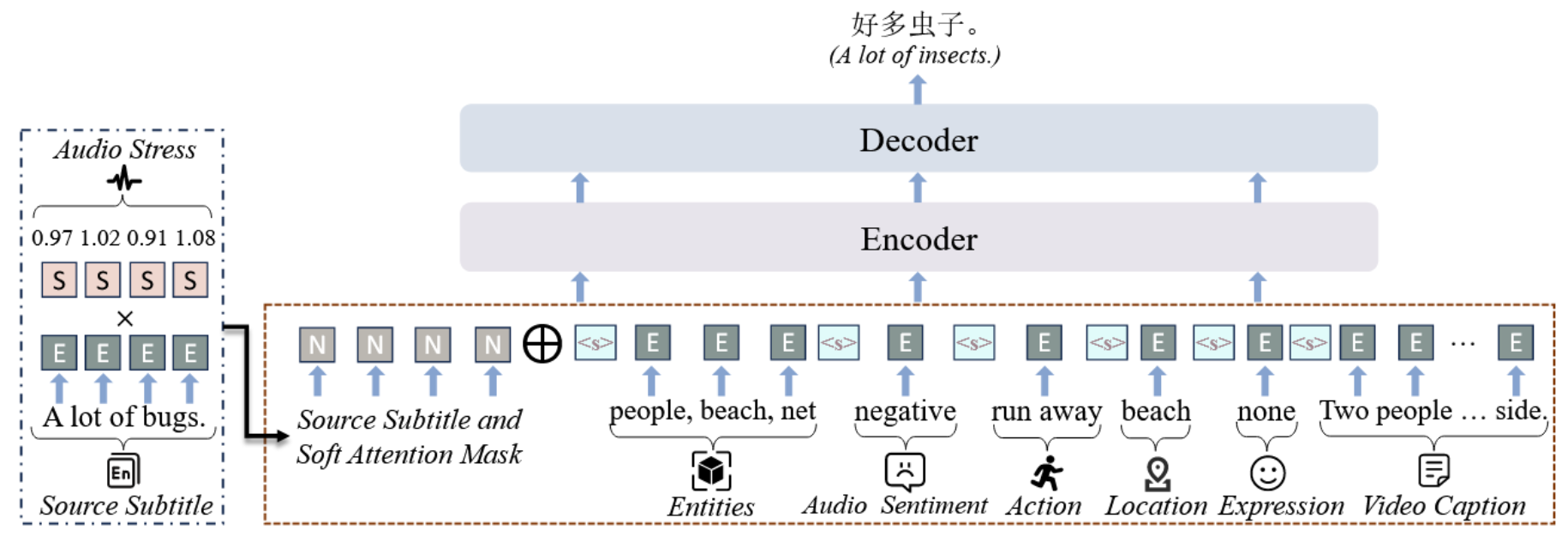
Recommended citation: TriFine: A Large-Scale Dataset of Vision-Audio-Subtitle for Tri-Modal Machine Translation and Benchmark with Fine-Grained Annotated Tags (Guan et al., COLING 2025)
Download Paper | Download Slides | Code | Dataset