
Boyu Guan (管博宇) - NLP and Multimodal LLM Research
I am currently a Ph.D. student at the Institute of Automation, Chinese Academy of Sciences, and a member of the State Key Laboratory of Multimodal Artificial Intelligence Systems, where I am advised by Prof. Chengqing Zong (宗成庆) and Assoc. Prof. Yang Zhao (赵阳).
My research lies at the intersection of Natural Language Processing (NLP) and Multimodal Large Language Models (MLLMs), with a current focus on Video-Guided Machine Translation (VMT). In this line of work, I explore how visual and linguistic signals can be effectively fused to enhance translation performance and efficiency.
Looking ahead, I am particularly interested in expanding my research to video question answering and broader topics in multimodal understanding.
If you’re interested in collaboration or would like to chat, feel free to reach out to me at guanboyu2022[at]ia.ac.cn.
📚 Education:
- 2022.09 – 2027.06 (Expected) Ph.D. in Computer Science at the Institute of Automation, Chinese Academy of Sciences, Beijing, China
- Research interests: Multimodal Large Language Models, Video Understanding, and Multilingual (Machine Translation)
- Conducted research under Prof. Chengqing Zong (宗成庆) at the State Key Laboratory of Multimodal Artificial Intelligence Systems.
- 2018.09 – 2022.06 B.Sc. in Mathematics, School of Science, Northeastern University, Shenyang, China
- GPA: 3.76 / 5.00, Rank 3 / 31; admitted to a direct PhD program via top-10% recommendation.
📰 News:
- 2026.04: 🎉🎉 Our paper was accepted to ACL 2026 main conference, but due to visa issues, we may be unable to attend in San Diego.
- 2025.09: 👨🏫 I will serve as a teaching assistant for the Fall 2025 undergraduate course Practical Natural Language Processing at the University of Chinese Academy of Sciences (UCAS).
- 2025.08: 🎉🎉 Our paper was accepted to EMNLP 2025 main conference, looking forward to seeing you in Suzhou.
- 2025.03: 👨🏫 I will serve as a teaching assistant for the Spring 2025 Natural Language Processing course for Ph.D. students at Zhongguancun Academy.
- 2024.12: 🎉🎉 Our paper was accepted to COLING 2025 (oral)! Looking forward to seeing you in Abu Dhabi.
- 2024.09: 👨🏫 I will serve as a teaching assistant for the Fall 2024 undergraduate course Practical Natural Language Processing at the University of Chinese Academy of Sciences (UCAS).
Publications
Video-guided Machine Translation
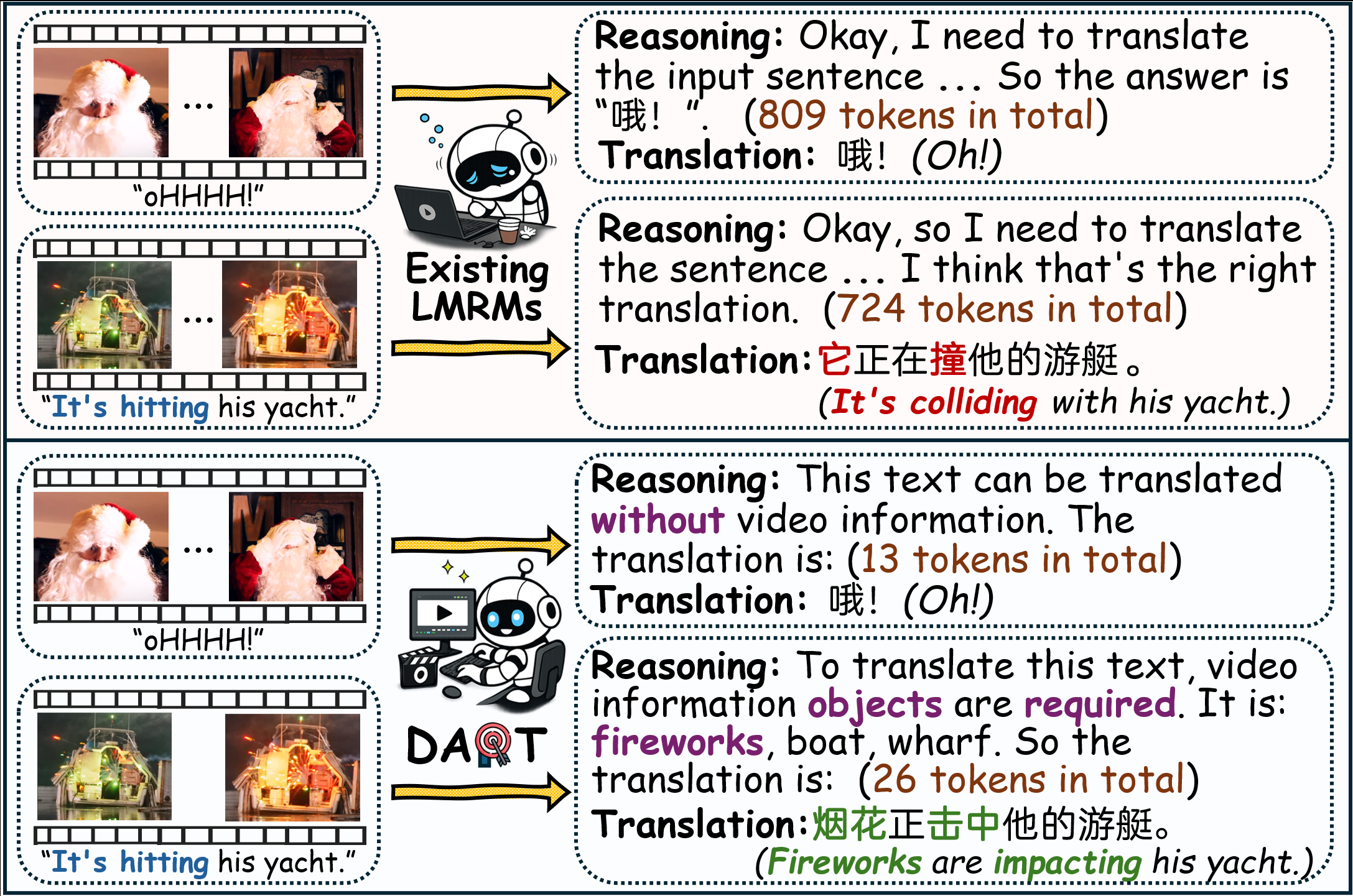
DART: Disambiguation-Aware Reasoning for Video-guided Machine Translation
This paper proposes DART, a framework for video-guided machine translation that adaptively decides when visual information is needed for translation. It also introduces TVRF, a filtering pipeline that identifies translation-relevant video cues. Experiments show that DART improves both translation quality and inference efficiency over strong baselines.
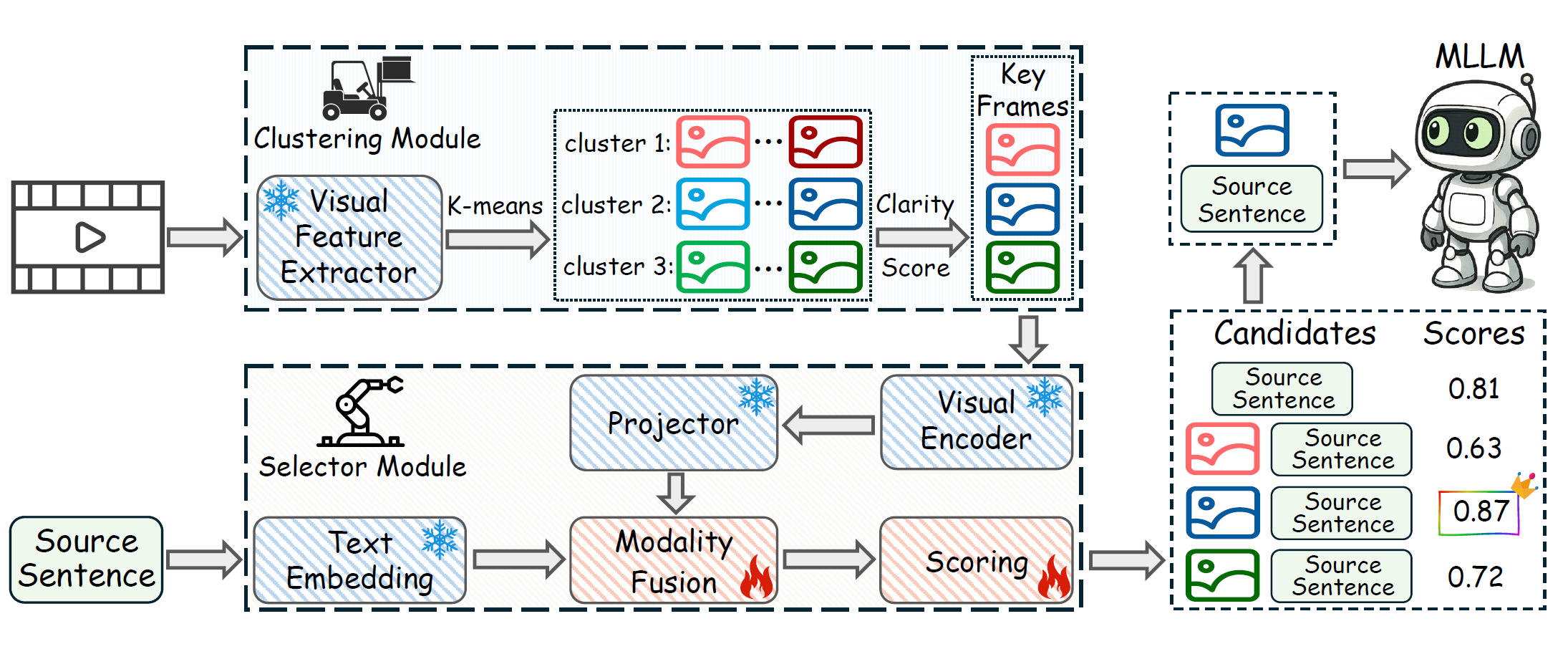
SHIFT: Selected Helpful Informative Frame for Video-guided Machine Translation
This paper introduces SHIFT (Selected Helpful Informative Frame for Translation), a lightweight, plug-and-play framework for video-guided machine translation (VMT) that adaptively selects only the most informative video frame—or none when unnecessary—to improve translation quality and efficiency using multimodal large language models (MLLMs).
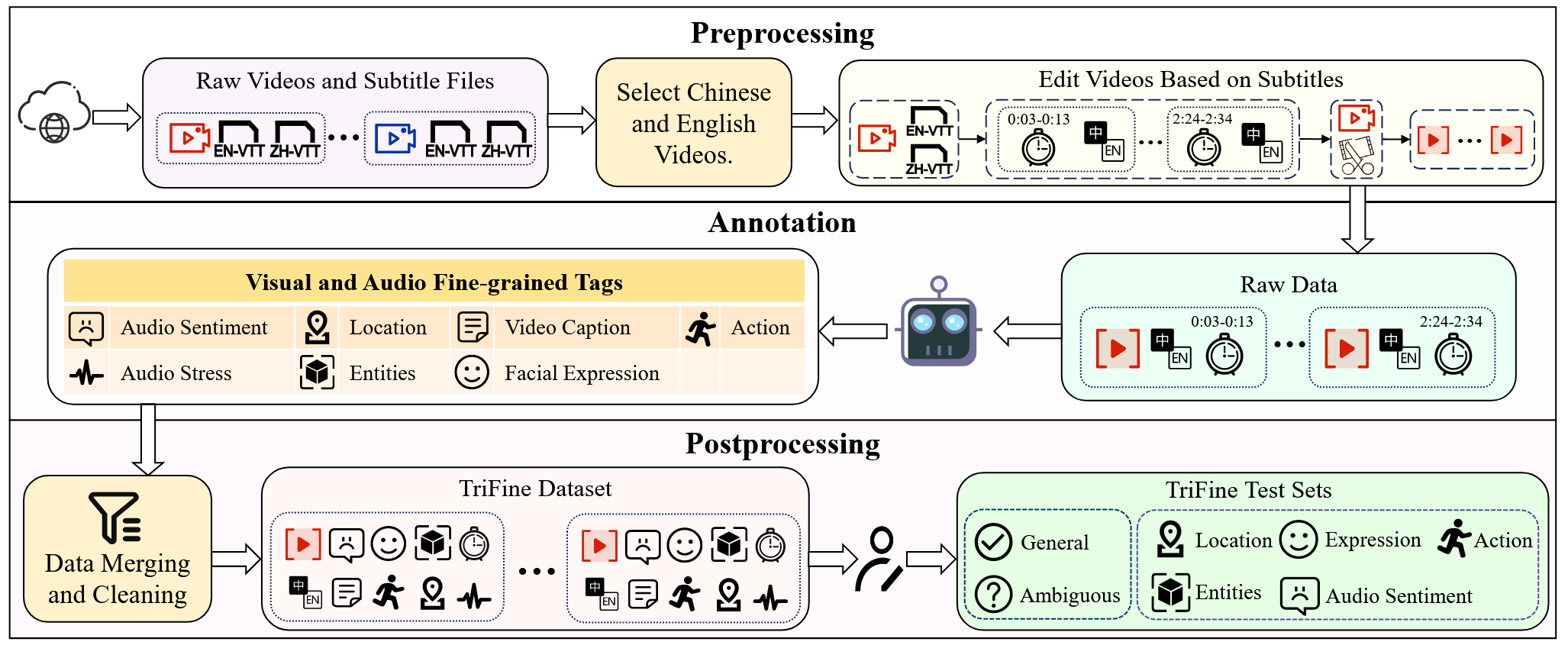
TriFine: A Large-Scale Dataset of Vision-Audio-Subtitle for Tri-Modal Machine Translation and Benchmark with Fine-Grained Annotated Tags
This paper introduces TriFine, the first large-scale dataset for tri-modal (vision, audio, subtitle) machine translation with fine-grained annotated tags, and proposes a novel translation method FIAT that leverages this fine-grained information to achieve superior translation performance.
Patent
1. A Video Machine Translation Method and Device Integrating Fine-Grained Multimodal Information
(Invention Patent Under Substantive Examination)
Authors: Yang Zhao (Advisor), Boyu Guan, Yining Zhang, Chengqing Zong
2. An Adaptive Key Frame Selection Method for Video Machine Translation
(Invention Patent Under Substantive Examination)
Authors: Yang Zhao (Advisor), Boyu Guan, Chuang Han, Chengqing Zong
💻 Internships
- 2025.11 – 2026.04 NLP Research Intern, Tencent, Beijing, China.
- Proposed PLAN, a compiler-inspired TKGQA framework that converts queries into deterministic stack-based execution, improving LLM stability in temporal reasoning and achieving SOTA performance. (One first-author paper)
- Worked on GUI agents, including multimodal data curation and large-scale (235B) distributed training, improving performance in complex multi-step tasks.
- 2023.02 – 2023.08 Software Engineering Intern, Biren Technology (壁仞科技), Beijing, China.
- Participated in adapting and optimizing large-scale model pre-training and inference pipelines, including porting key mechanisms such as activation checkpointing and 3D parallelism, and integrating training frameworks DeepSpeed and Megatron-DeepSpeed.
- Conducted operator extraction, migration, and end-to-end pipeline optimization for mainstream LLMs (e.g., LLaMA, LLaMA2, Qwen), improving overall training and inference performance.